【創科廣場】FB AAT便利視障用戶 更易了解圖片內容
2021-02-05 13:00社交媒體平台早已與日常生活環環相扣,最常見分享的內容當然是相片,無論上載生活相片及更新近況,直至「相機食先」文化出現,以相片分享日常點滴,已經成為大眾的生活習慣。雖然facebook或Instagram用戶經常滑動成千上萬的照片,但對於視障人士說,未必能完全了解海量的網上社交平台的相片。
一般將圖片上載至網站,都會在HTML代碼使用Alt替代文字,這並非facebook,而是單純指出圖片的內容,例如描述圖片的外觀及功能。此舉不但可在網民用戶無法下載圖片時,網站可以利用Alt替代文字顯示圖片位置,更是必做的SEO技巧,為搜尋引擎提供更好的圖片描述,協助正確地將圖片提供索引。因此,以往當視障用戶透過屏幕閱讀器瀏覽facebook內容時,遇到圖像就會透過聽到合成話音描述以播報形式讀出「照片」一詞,然後分享圖片的發布者名字。
畫面描述變得更具體
由於互聯網速度愈走愈快,Alt文字對於普羅大眾而言已不再是必須。再者若文字的描述單靠上傳圖像的人手添加,則未必完全可靠。
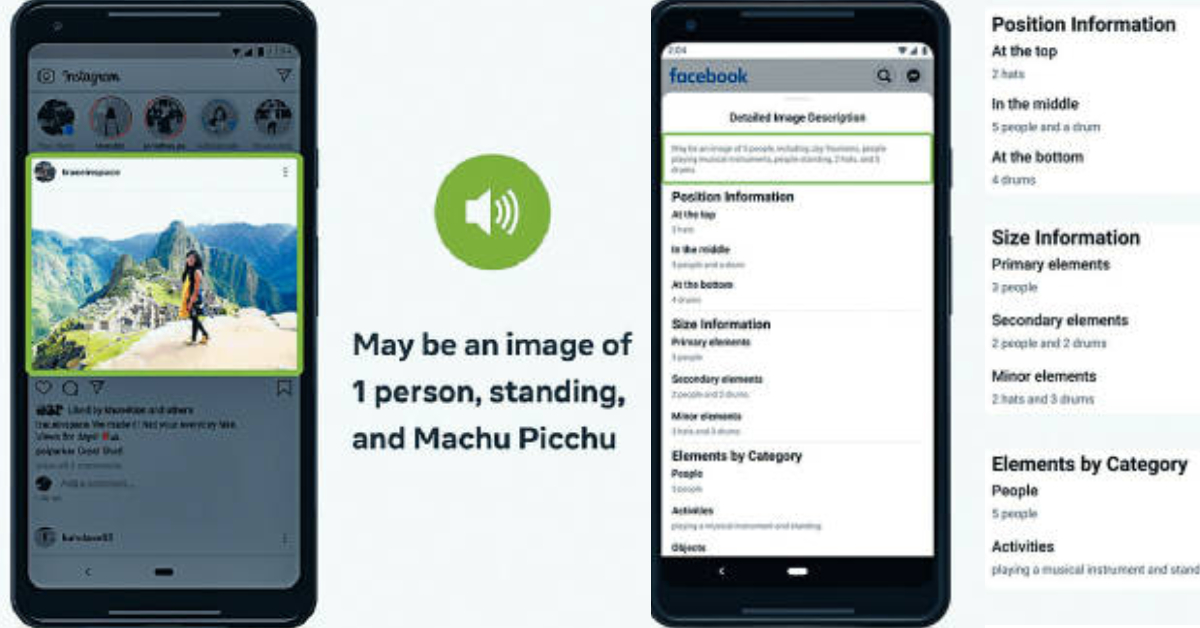
由於許多上載到社交媒體平台的圖片都沒有附加Alt文字,facebook在2016年引入一項自動替代文字(Automatic Alternative Text,AAT)新技術,其後在2018年更獲美國盲人基金會頒發Helen Keller Achievement Award成就獎。這項技術經過多番測試,最近更作出重大改變,令照片識別的可認度大大提升,既能識別活動、地標、動物類型等,甚至在照片中加入潛在位置,辨識更多相片當中的內容,將畫面描述變得更具體,令視障用戶有機會讀取圖片內容。
根據facebook在其tech@facebook網誌,AAT第一個版本是使用人類標的數據開發,透過數據將數百萬個案例訓練最新版本的AAT模型。完整的AAT模型可識別例如「樹」、「山」等100個常見概念,亦會靠人面辨識技術識別相片中的內容是「人」。其後因為利用標記數據花費太多時間精力,因此後來演變成利用一個以數十億張公開的Instagram圖片及其標籤的形式進行數據訓練的模型,並進行微調,可從所有地理位置的圖像擷取數據,利用多種語言的主題標籤翻譯,並透過文化及人口統計學的蛛絲馬迹了解圖片內容。例如不必僅僅單靠註解為白色婚紗的照片,也可利用傳統服裝識別世界各地的婚禮。
亦能了解社交網站銷售內容
其後由facebook AI Research開發使用Detectron2訓練一個稱為Faster R-CNN的檢測器作為開源平台,預測圖像中的對象位置和語義標籤,透過採集多標籤及多數據,令其模型變得更為可靠,可識別1200多個概念,比最初發布的原始版本多達十倍。不過為求精準,facebook也會在每個描述以「可能會」(Maybe)作為開頭以免有誤差或歧義。現時所有替代文本說明,可用45種不同語言列出。
新版本的AAT自動替代文本技術使相片描述更精準及更容易明白,更進一步幫助視障用戶理解家人和朋友在社交媒體平台發布的照片內容,同時亦能了解社交媒體網站銷售內容。此舉對於普遍用戶來說,或未必輕易察覺,但這項技術彌合了過往的差距。對於視障用戶來說,可能對於社交媒體有更深層的另一番體會。
關鍵字
最新回應