【 创科广场】Adobe推内容撷取API 释放PDF更多内容
2021-08-20 09:19
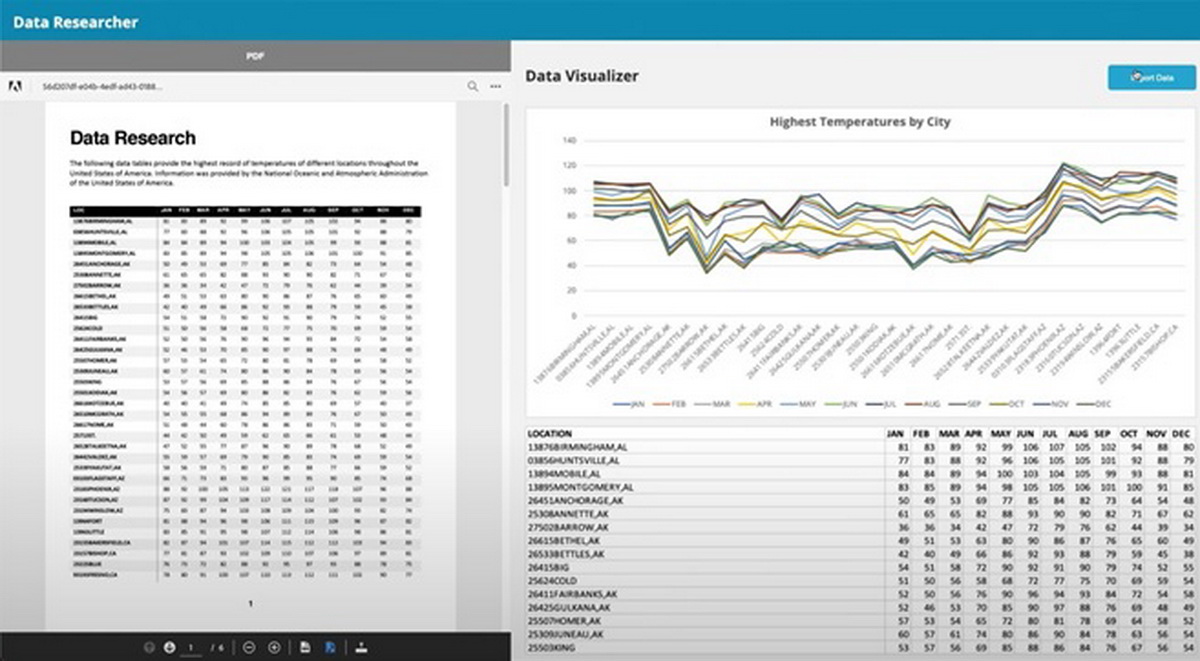
企业可按用途需要,使用PDF Extract API快速准确地提取数据。
Adobe Document Generation API还包括了与Adobe Sign作整合、开箱即用工具,随时可在档案中使用电子签名,以产生发票和报价等文件。
从PDF撷取内容,往往必须靠光学字元辨识(OCR)工具,扫描PDF文件并找出内容,甚至是表格内容,表格上不同位置的数据,OCR有不少限制,也未必可完全准确撷取文件内容和属性,有时要以不同工具,甚至靠人手核对。
市场上PDF文件可通过不同系统生成,例如是ERP系统,从Word或Excel和其他文件转存而成,甚至从影像扫描产生,部分系统只产生供人类阅读的PDF,从未预计最终要与机器沟通,以至PDF从个别系统生成后,结构并不容易供电脑辨认,如果辨认表格,就更加麻烦。
以编程生成动态数据
虽然RPA工具可通过人工智能,决定文件上某个位置数据;市场上领先工具ABBYY,亦可准确辨认不同PDF,但往往不能解决全部问题;开发人员动用多种工具,才取出PDF所有数据。
系统辨认PDF,往往要先搞清楚从那个系统产生,如果开发人员可以有更好的应用程式界面,就可以快速撷取内容、图片、位置,甚至位置和表格,市场上有不少云端的工具,以撷取PDF内容;例如是PDF.co(https://pdf.co/),并整合到不同工具或系统,从PDF提取内容已成为一门大行业。
Adobe是PDF的开发厂商,推出了Adobe PDF Extract API和Adobe Document Generation API两个应用程式界面,有助解决PDF文件内容交换难题,协助撷取更多PDF文件内容,以编程方式生成具动态数据的档案。
云端为基础API
PDF几乎成为可携化文件的统一标准,而以云端为基础API,可协助开发人员加速开发。Adobe已开发PDF文件30年,其Adobe电子档案服务、以云端为基础API和SDK,已经可让开发人员开发方案。
Adobe估算,每年约有2.5万亿个新创建PDF档案。Adobe PDF Extract API 乃建基于Liquid Mode,也是以云端为基础的API,同时分析来自扫描和原生PDF的结构,再提取文字、表格数据、图像等所有PDF元素,了解相对位置、跨栏和分页的阅读顺序。
据Adobe公布,PDF Extract API的优势,在于可提取所有的PDF元素,不少API仅限提取某一种类型元素。此外,许多供应商也有指定平台;Adobe所有API,包括PDF Extract API则可使用任何现代编程语言或者平台,并准确地提取数据以用于机器学习模型、分析、制作索引或储存,整合RPA和自然语言处理(Natural Language Processing,NLP)等下游流程自动化,重新发布适用于多个媒体的PDF内容。
而Adobe Document Generation API则可让开发人员快速设计自订Microsoft Word范本,以及生成具动态数据Word和PDF档。
Document Generation API还包括了与Adobe Sign作整合、开箱即用工具,随时可在档案中使用电子签名,以产生发票和报价等文件。Document Generation API还可与适用于Microsoft Power Automate的 Adobe PDF Tools连接器一起使用,Power Platform能自动化预备发票、协议等档案流程。
關鍵字
最新回应